会社で、Redshiftのノードについて説明してほしいと依頼があったので、データウェアハウスシステムのアーキテクチャ - Amazon Redshiftの内容を要約しました。
2017/02/15時点の情報です。
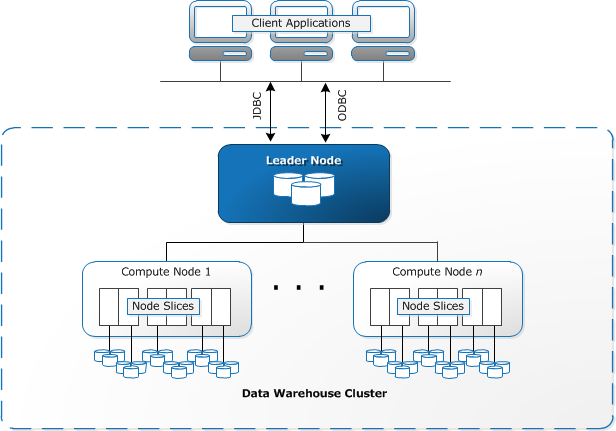
http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/images/02-NodeRelationships.png
ノードの種類
ノードには、リーダーノード(図"Leader Node")と、コンピューティングノード(図"Compute Node")の2種類があります。
1つのクラスターは、1つのリーダーノードと1 つまたは複数のコンピューティングノードで構成されます。
※リーダーノードがない構成にもできますが、話をシンプルにするためにここでは割愛します。
ノードの役割
リーダーノードとコンピューティングノードの2種類があります。
- リーダーノードは、クラスタのすべての通信を管理します。
- コンピューティングノードは、実際の処理を行います。
ノードを増強することによるメリット
処理能力(CPU、メモリ)が上がり、ストレージ容量が増えます。
増強の方法
2種類あります。
- ノードの数を増やす
- ノードの種類をアップグレードする
※増強できるのは、コンピューティングノードです。リーダーノードはできません。
コンピューティングノードのタイプ
コンピューティングノードのタイプについて、説明します。
DS(高密度ストレージノードタイプ )
DSは、ストレージに最適化されています。 HDD です。
- DSは、DS1とDS2の2種類があります。
- DS2は、DS1と比べてよりパフォーマンスが高いです。(メモリ、CPUが高スペック)
DC(高密度コンピューティングノードタイプ)
DCは、コンピューティングに最適化されています。 SSD です。
- DCは、DC1の1種類しかありません。
ノードスライスとは?
※図では、"Compute Node n"ですが、わかりやすくするために、ここではn = 2とします。
- コンピューティングノードは、複数のノードスライスから構成されています。
- 1ノードに6スライスあるので、全部で12スライスになります。
- ノードスライスには、それぞれ独立したCPU、メモリ、ストレージが割り当てられ、並列処理されます。
- 1ノードあたりのスライス数は、ノードのタイプによって決まります。スライス数を変更することはできません。
データ分散の方法
- データは全12のノードスライスに分散されます。
- 異なるノードスライスのデータをJOINすると処理が重くなるので、それを避けるように分散方法を指定します。
分散キーの考え方
データの分散方法を指定するには、分散キーを指定します。
- 分散キーは、テーブルをCreateするときに指定します。
- JOINするときを想定して、分散キーにはJOINのキーとなるカラムを指定します。
次のような感じです。
-- 購買テーブル create table purchase ( item_id int, -- 商品ID purchase_time timestamp ) distkey (item_id); -- 商品マスタ create table products { item_id int -- 商品ID item_name varchar(255) ) distkey (item_id); -- 商品IDで結合 select * from purchase p1 inner join products p2 on p1.item_id = p2.item_id;
この例では、購買テーブルと商品マスタは商品IDでJOINされることがわかっているので、テーブルをCreateするときに商品IDを分散キーに指定しています。そうすると、必要なデータはすべて同一のスライスにあるので、JOINしてもパフォーマンスは劣化しません。